Jul. 2023 | ZSCL: Fine-tuning VL Models w.o. Zero-Shot Degradation
Zangwei Zheng, zangwei@u.nus.edu
National University of SingaporeICCV 2023
Other version: [arXiv] [Code] [中文]Discuss on twitter with the author.
TL;DR
Large vision-language models have the ability to make predictions on various tasks without the need for fine-tuning. However, continuously fine-tuning these models can lead to improved performance on new data or tasks. Nevertheless, we have observed a significant decline in zero-shot performance on other datasets when models undergo continual learning. To address this issue, we propose a straightforward yet effective approach that involves constraining both the feature space and parameter space of the model. Our method not only outperforms the zero-shot model on downstream tasks but also maintains its zero-shot transferability to other tasks.
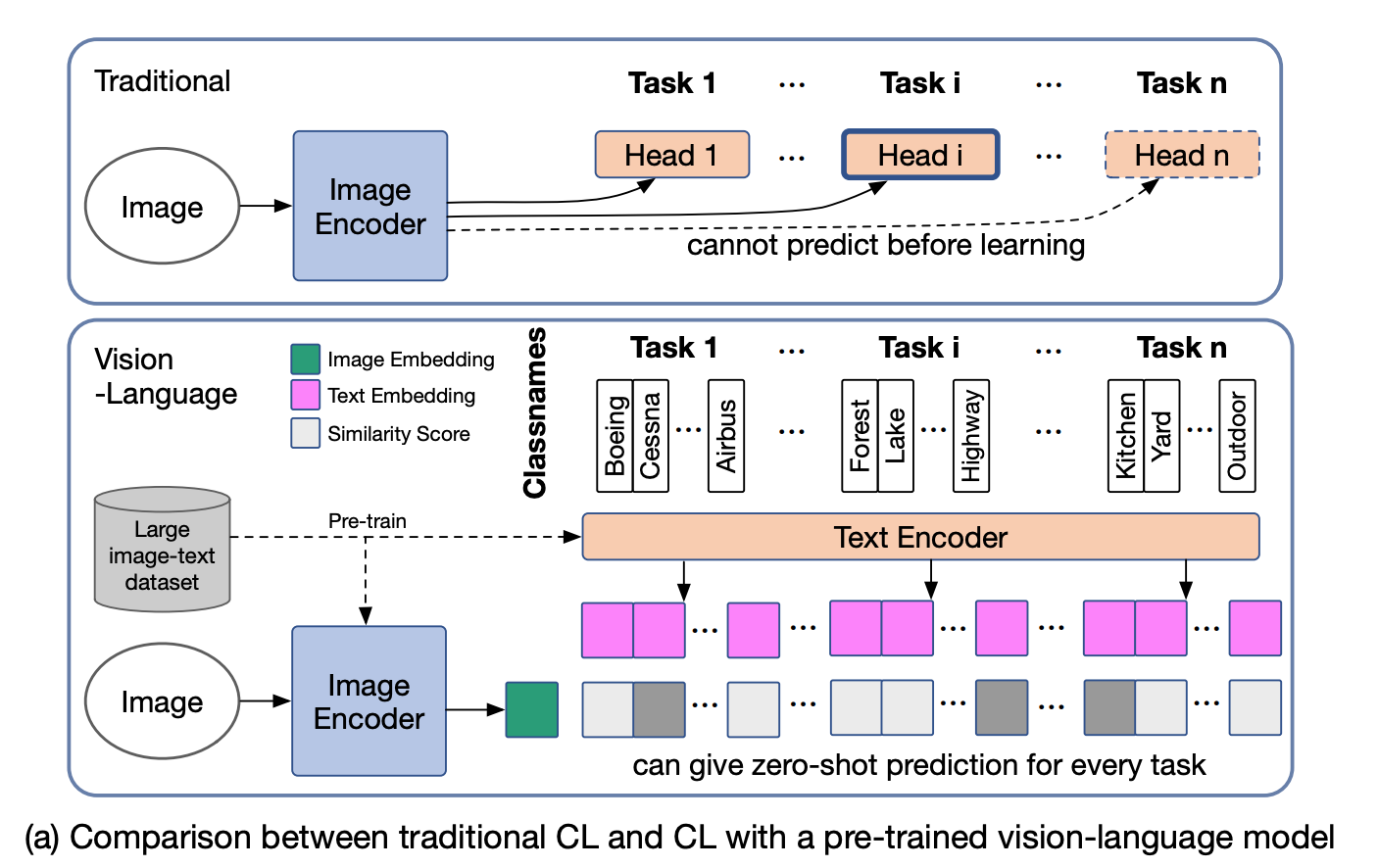
Catastrophic Forgetting in Fine-tuning Vision-Language Models
Catastrophic forgetting refers to the phenomenon where a model, when trained on a new task, loses its ability to perform well on a previously learned task. This issue also affects the zero-shot transfer capability of vision-language models obtained through pretraining. To address and evaluate this problem, we introduce a novel benchmark known as Multi-domain Task Incremental Learning (MTIL). This benchmark comprises eleven domains with highly distinct semantics. A selection of these domains is provided below.

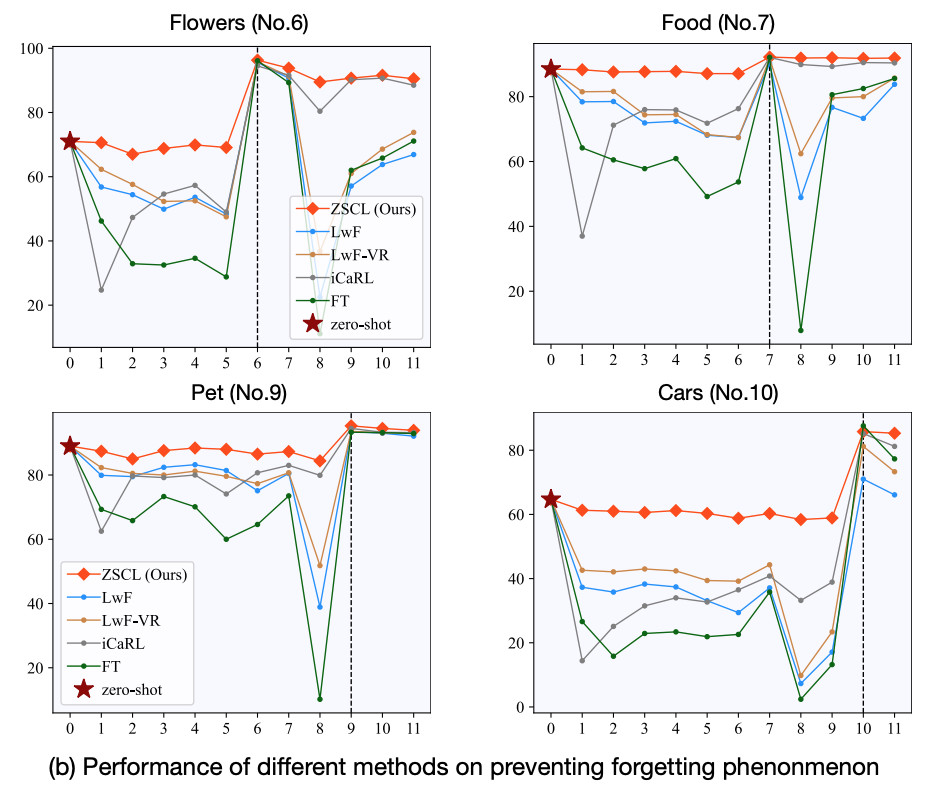
During sequential training of a pre-trained vision-language model (such as CLIP) on various tasks, we have observed a notable decrease in zero-shot performance on other datasets. The figure presented below illustrates the performance across four domains during the training of eleven domains. Prior to fine-tuning on the respective domain, each dataset experiences a substantial decline in zero-shot performance (indicated by the green line). While other methods attempt to alleviate this issue, they still exhibit a considerable decrease in zero-shot performance. In contrast, our proposed method (represented by the red line) effectively maintains the model’s zero-shot performance.
Constraints in Feature Space and Parameter Space
The knowledge of a pre-trained vision-language model can be viewed as stored within two key components: the feature space and the parameter space. The feature space refers to the output generated by the model’s final layer, while the parameter space encompasses the model’s weights. To address the issue of catastrophic forgetting, we propose the application of constraints to both the feature space and parameter space.
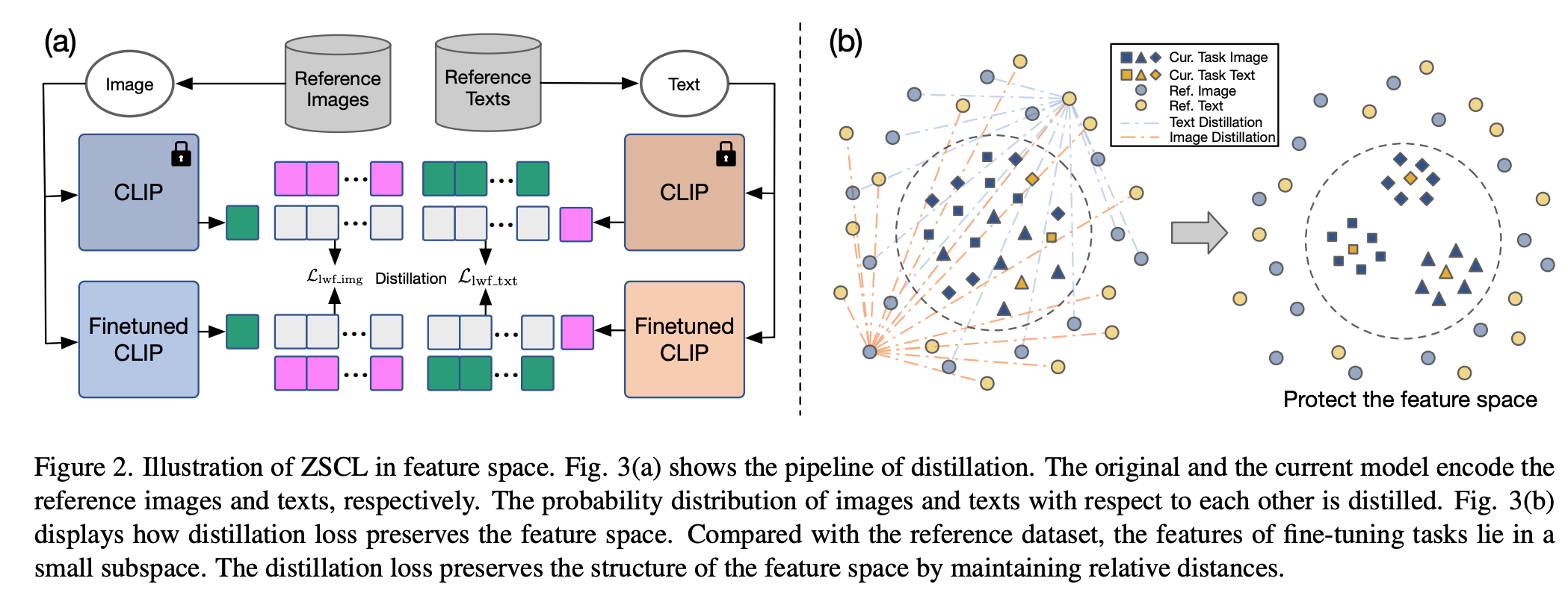
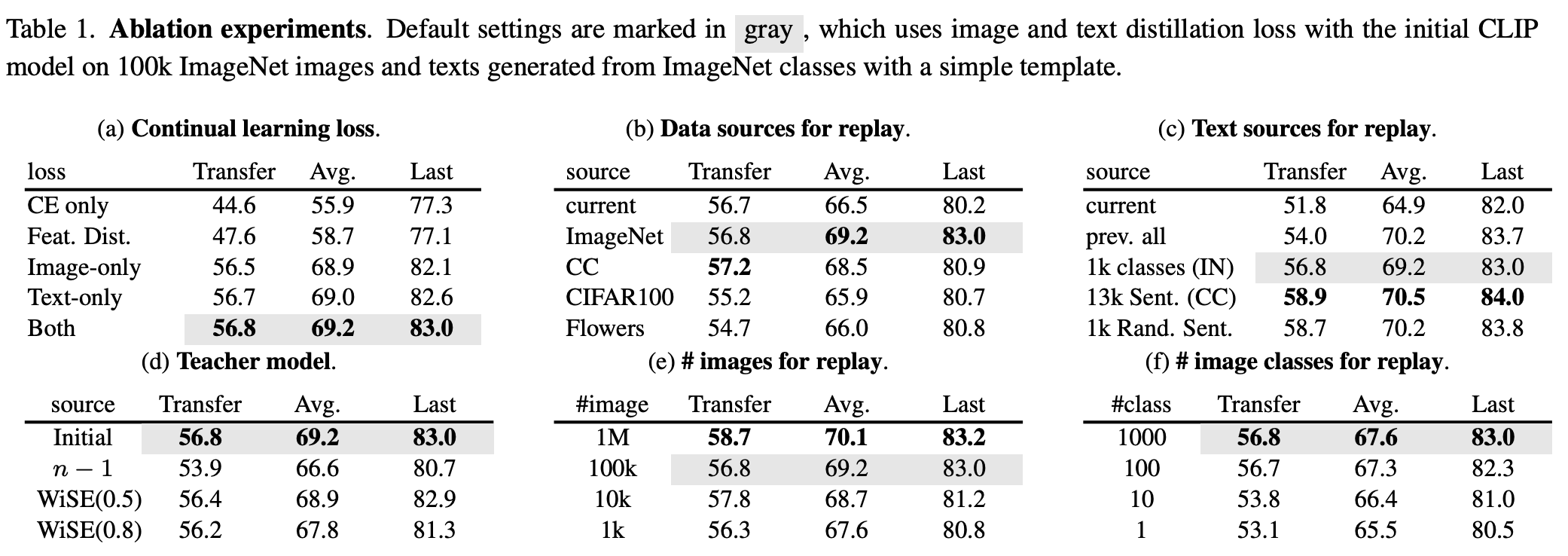
Within the feature space, we employ an LwF-style loss to encourage the model’s output to resemble that of the pre-trained model. The loss is defined as $\mathcal{L}=\text{CE}(\bm{p},\bm{\overline{p}})=-\sum_{j=1}^m\bm{p}_j\cdot\log\bm{\overline{p}}_j$, and it is applied to both the text and image components. The key distinction between our approach and LwF lies in the introduction of reference datasets and a reference model. The reference dataset should possess semantic diversity and does not necessarily need to be labeled, pre-trained, or contain matched image-text pairs. Meanwhile, the reference model refers to the pre-trained model itself, rather than the model trained on the previous task as in LwF. Further details and ablation studies involving various choices are presented in the accompanying figure.
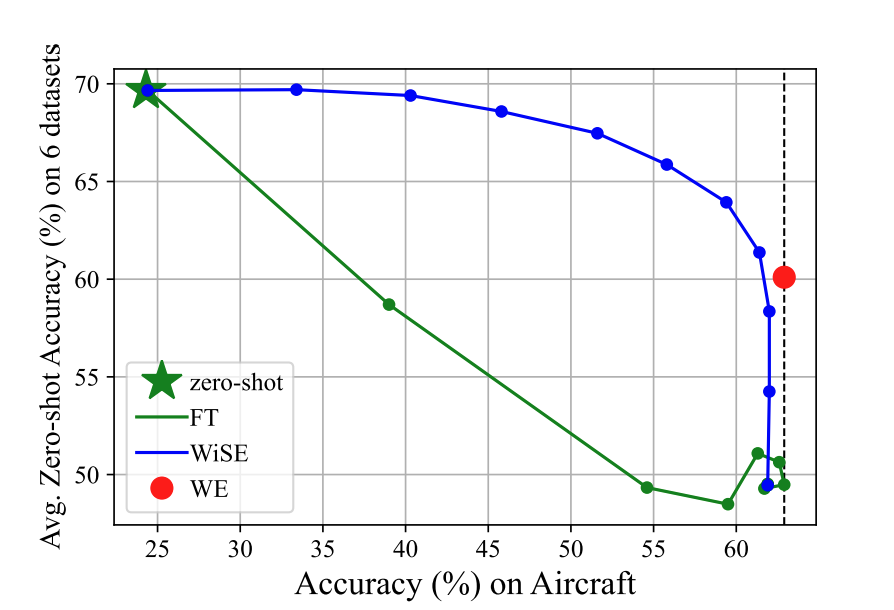
In the parameter space, we draw inspiration from WiSE-FT, which combines the fine-tuned model and the pre-trained model to achieve an improved balance between zero-shot performance and task-specific performance. We observe that model checkpoints obtained during training can be seen as different trade-offs. Therefore, we can create an ensemble of these models to better retain parameter knowledge. This update process bears similarities to Stochastic Weight Averaging (SWA):
$$ \begin{equation} \hat{\theta}t = \begin{cases} \theta_0 & t=0 \ \frac{1}{t+1}{\theta}{t} + \frac{t}{t+1}\cdot\hat{\theta}_{t-1} & \text{every I iterations} \end{cases}. \end{equation} $$
Results
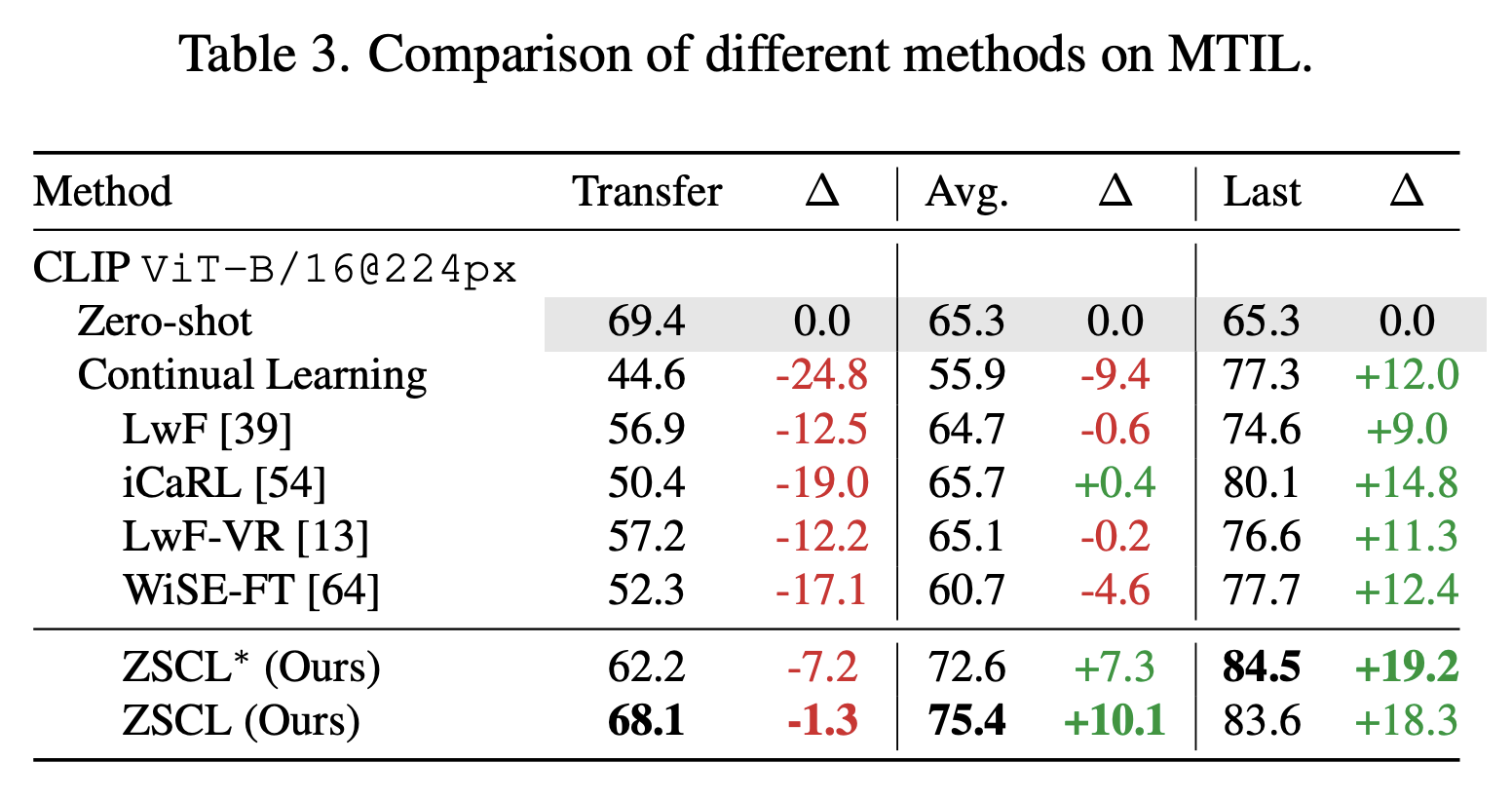
We assess the effectiveness of our method on both our Multi-domain Task Incremental Learning (MTIL) benchmark and traditional incremental learning datasets. Here, we present the results specifically for the MTIL benchmark. Within this benchmark, the Transfer metric gauges the performance on previously unseen datasets, while the Last metric represents the final performance achieved after all the continuous learning steps. Our method demonstrates a significant enhancement in the Last performance, with only a minimal decrease in the Transfer performance. This indicates that our approach effectively improves the model’s overall performance while maintaining its ability to transfer knowledge to new tasks.
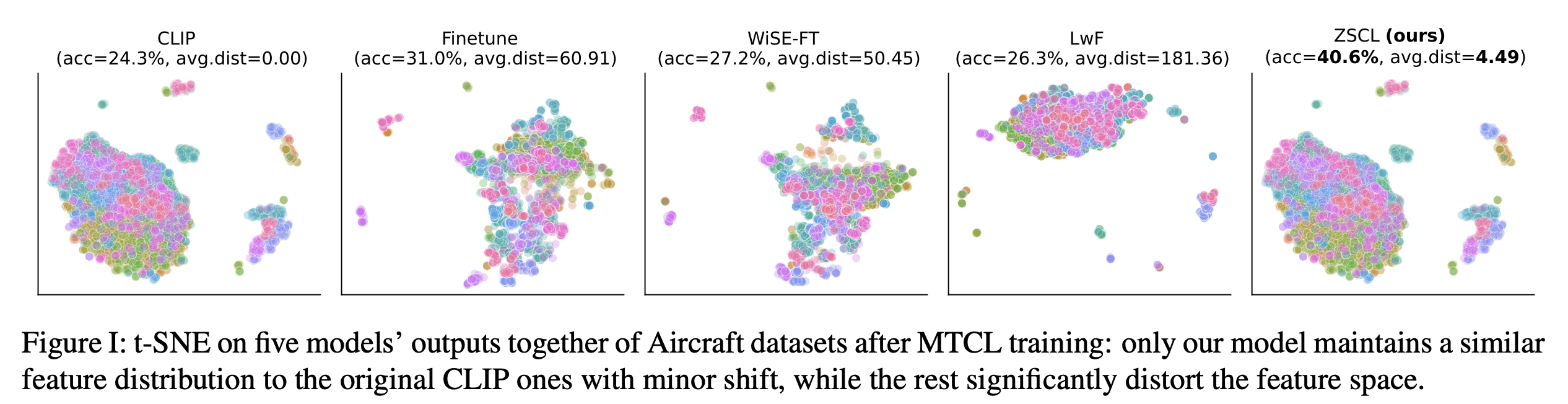
We visualize the feature space of the Aircraft dataset after applying MTIL. By collecting the features from the outputs of five models and applying t-SNE, we can observe the distribution of the features. The figure below demonstrates that our method is successful in preserving the feature space of the pre-trained model, resulting in an almost identical feature space to that of the original pre-trained model. This visualization indicates that our method effectively retains the important features of the pre-trained model throughout the MTIL process.
Discussion
In the era of large-scale models, traditional continual learning from scratch may have become less practically significant. However, the ability to fine-tune a pre-trained model on new tasks remains crucial. Incorporating the latest information, adding domain-specific knowledge, or rectifying mistakes in the pre-trained model are all potential applications. Continual learning proves to be a much more efficient approach compared to re-collecting datasets and retraining the model from scratch. Our paper addresses the zero-shot transfer degradation in this task and evaluates our method on the CLIP model. As language and vision models gain popularity, extending the application of our method to multimodal models such as MiniGPT4 and LLaVA holds promising prospects.