May 2023 | Sequence Schedule: Can we use LLM to Speedup LLM inference?
Zangwei Zheng, zangwei@u.nus.edu
National University of SingaporeOther version: [arXiv] [Code] [中文]
Discuss on twitter with the author.
TL;DR
We find that large language models (LLMs) have the remarkable ability to perceive the length of their generated responses in advance. Leveraging this LLM ability, we propose a novel technique called Sequence Scheduling to improve the efficiency of LLM batch inference. By grouping queries with similar perceived response lengths together, we significantly reduce redundant computations and achieve an impressive 86% improvement in inference throughput without compromising performance.
LLM is aware of its response length
We begin our investigation by examining whether LLMs possess the ability to perceive the length of their generated responses. To investigate the response length perception ability of LLMs, we designed a prompt technique called “Perception in Advance (PiA)” that ask the model to predict the length of its generated response.
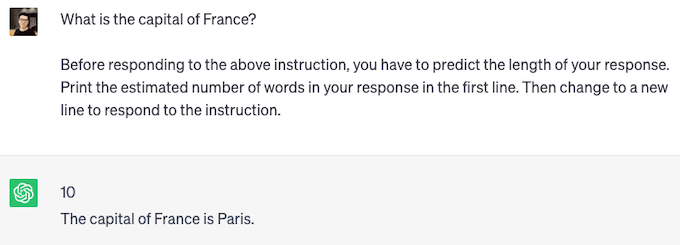
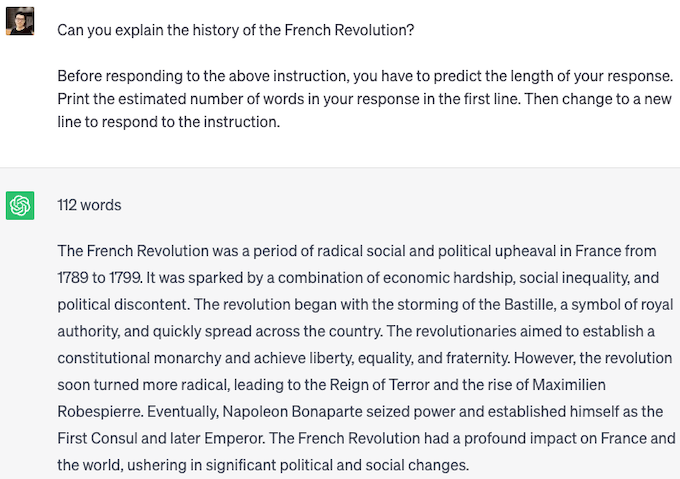
We find that popular LLMs such as GPT-4, ChatGPT, and Vicuna, can follow the instruction and give a response length estimation. The above two figures are examples of PiA with ChatGPT. For the short one, ChatGPT perceived of length 10 words with real length 6 words. For the long one, ChatGPT perceived of length 112 words with real length 119 words. ChatGPT may not be explicitly trained with response length prediction, but it accurately estimates the length of generated responses.
Instruction tuning improves response length perception
For open-source instruction-finetuned language models (LLMs) like Vicuna-7B, accurately perceiving the length of responses remains a challenge. When considering estimates within a range of 100 words as accurate, it only achieves a 65% accuracy(100) on the Alpaca dataset. Furthermore, LLMs have a weaker grasp of tokens compared to words, which hinders their ability to improve inference.
In order to enhance the model’s proficiency in perceiving response length, we developed a dataset comprising pairs of instructions and their corresponding token lengths. Leveraging efficient instruction tuning with LoRA, we sought to bolster its performance. As a result of this tuning process, the model achieves an improved accuracy(100) of 81% on the Alpaca dataset.
LLM batch inference
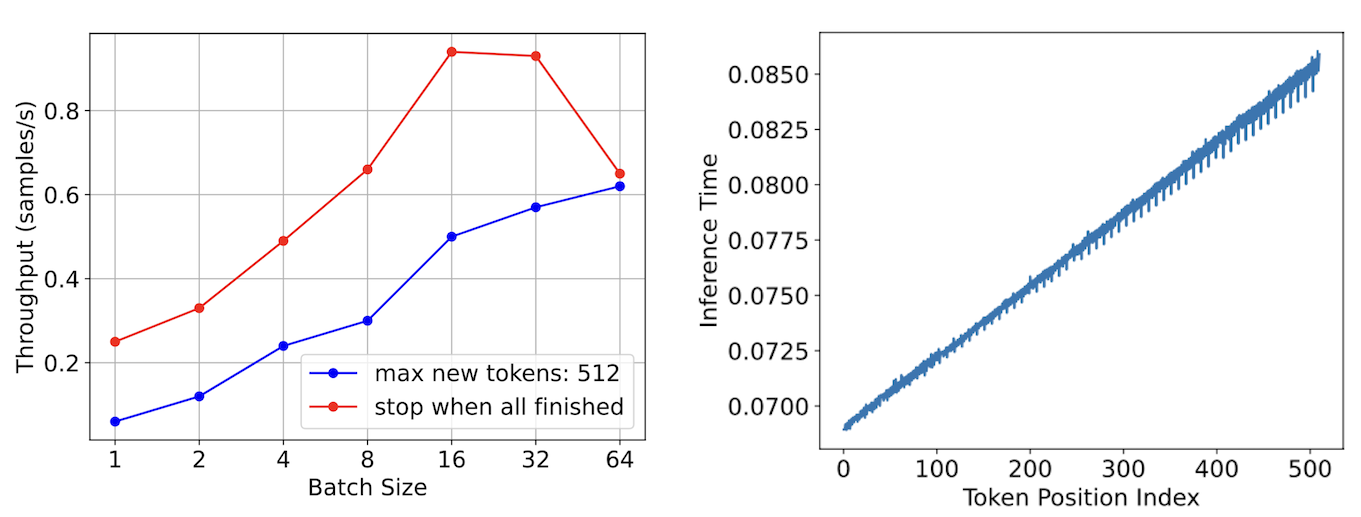
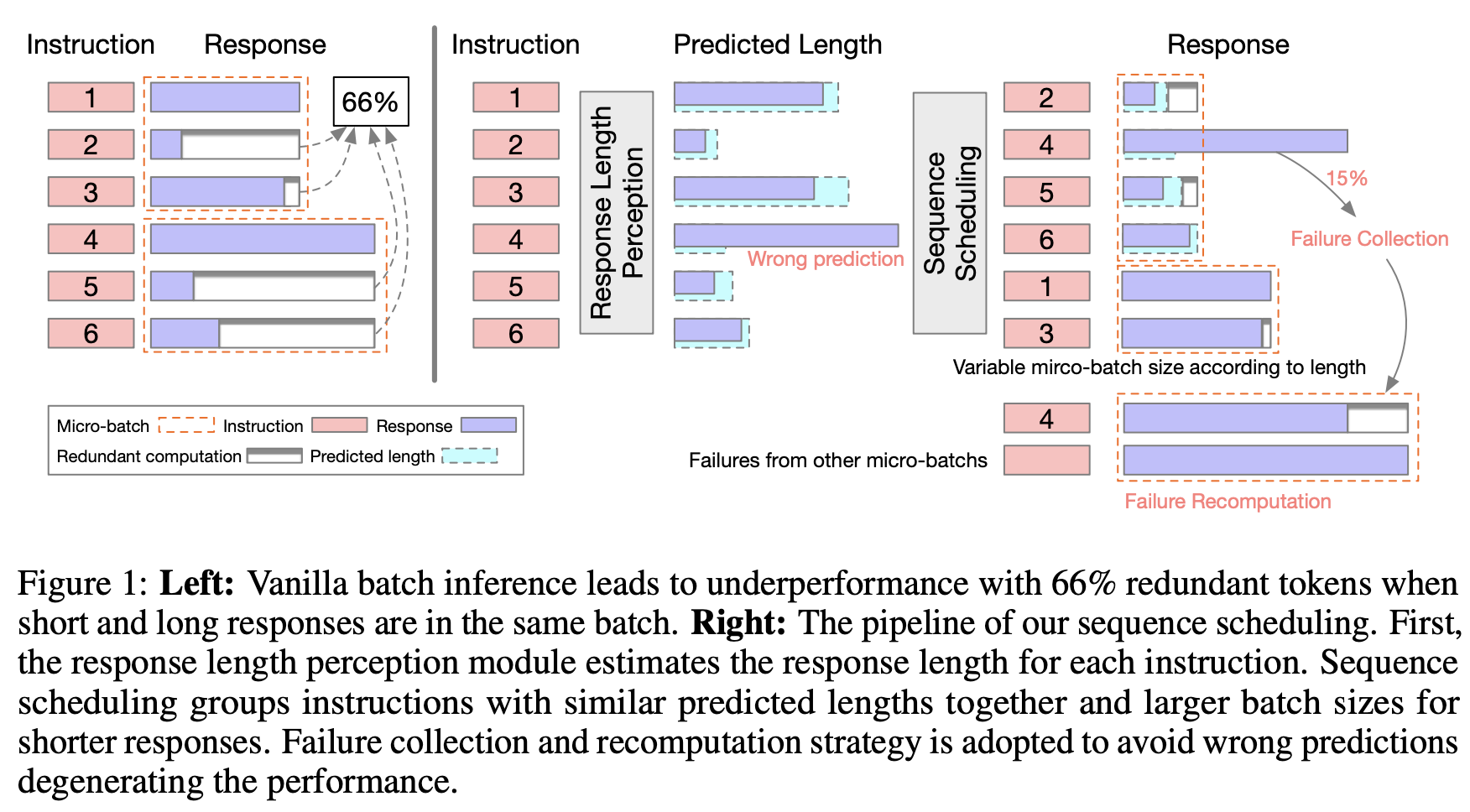
Let’s now focus on the inference process of the LLM. Batch inference is a commonly used technique to enhance the efficiency of inference. In the figure on the left side, we observe that as the batch size increases, the inference throughput also increases almost linearly (as indicated by the blue line). However, when performing LLM inference in batches, incorporating sequences with varying response lengths introduces inefficiencies. Shorter sequences have to wait for longer ones to complete, resulting in reduced efficiency. We have found that approximately 66% of the computations performed are redundant. As the batch size continues to grow, the throughput performance starts to decline (as shown by the red line). This decline occurs because larger batch sizes have a higher likelihood of including longer response lengths, leading to a significant increase in redundant computations.
Furthermore, the figure on the right side demonstrates that the inference time increases with the token position index. This increase is due to the requirement of performing self-attention operations on a greater number of keys and values.
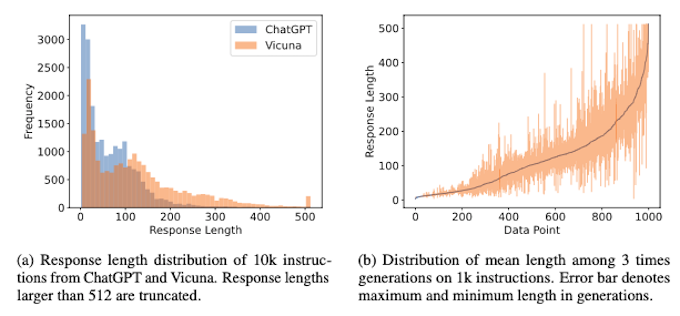
In real-world scenarios, the response length of queries varies as shown on the length distribution of queries in the Alpaca dataset for ChatGPT and Vicuna models (left side of the figure). This highlights the need to address the issue of varying response lengths in LLM inference. Furthermore, on the right side, we observe that different samplings of the same data point can result in different lengths, adding to the complexity of perceiving and handling response lengths.
Sequence Scheculing via Response Length Perception
We propose a novel technique called Sequence Scheduling to improve the efficiency of LLM batch inference. By organizing queries with similar perceived response lengths into groups, we can significantly minimize redundant computations, resulting in a remarkable 42% improvement in throughput.
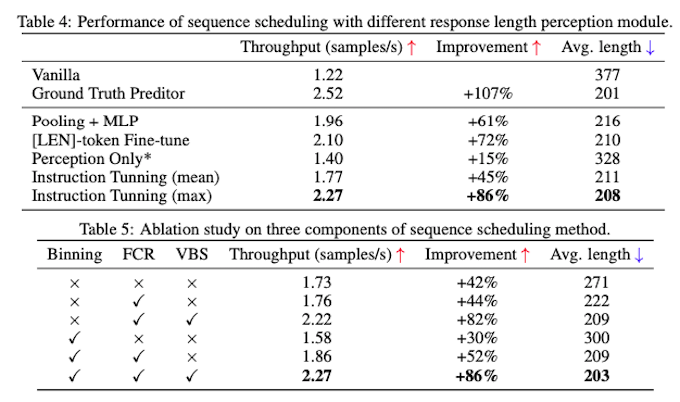
To further optimize the throughput, we introduce several additional techniques. Implementing these techniques collectively leads to an impressive 86% enhancement in inference throughput without compromising performance.
- Failure Collection and Recomputation (FCR): We limit the number of newly generated tokens to be at most the maximum predicted length within a batch. Instructions that exceed this predicted length are deemed failures and are separated for recomputation at the end of the inference process for a group of a specific size. Given the relatively low failure ratio, this approach enables faster generation of shorter responses while minimizing the time spent on regenerating failed instructions.
- Variable Batch Size (VBS): We assign a larger batch size for shorter responses. This approach allows us to process more queries simultaneously, thereby optimizing the overall throughput.
- Max Length Prediction: The response length perception module predicts the maximum length of multiple sampled responses. Underestimation of response length has more severe consequences compared to overestimation. Therefore, we prioritize accurately predicting the maximum length to avoid truncation and ensure the desired response length.
- Binning: We group queries with similar response lengths into bins. This allows us to reduce the number of bins and allows for more efficient scheduling.
Discussion
In this study, we leverage the capabilities of LLMs to enhance their own inference process, leading to the development of what we refer to as an “LLM-Empowered LLM Inference Pipeline.” This approach can be viewed as a software-hardware co-design within the realm of AI, and we believe it holds great promise for future research endeavors.
Our research findings demonstrate that LLMs possess a profound understanding of the responses they generate. This insight presents exciting opportunities for devising faster inference techniques, such as non-autoregressive methods, that can overcome the limitations associated with sequential token generation and significantly improve performance.
As LLMs have the potential to become a pervasive infrastructure akin to search engines, the volume of queries they handle is expected to rise significantly. Moreover, the advent of models like GPT-4, which supports sequence lengths of up to 32k, and Claude, with a 100K sequence length support, further exacerbates the challenge of accommodating varying response lengths. In this context, our approach stands out for its relevance and effectiveness in addressing this challenge.