Jan. 2024 | Infobatch: Dataset Pruning On The Fly
Zangwei Zheng, zangwei@u.nus.edu
National University of SingaporeICLR 2024 Oral
Other version: [arXiv] [Code] [中文]
Discuss on twitter with the author.
TL;DR
Multi-epoch training can be accelerated by skipping well-learned samples or easy samples. Infobatch is a dynamic data pruning method that rescales the loss and update the data sampler on the fly for lossless performance. It achieves 20% to 40% speedup on tasks ranging from image classification, semantic segmentation, vision pertaining, diffusion model, and LLM instruction fine-tuning.
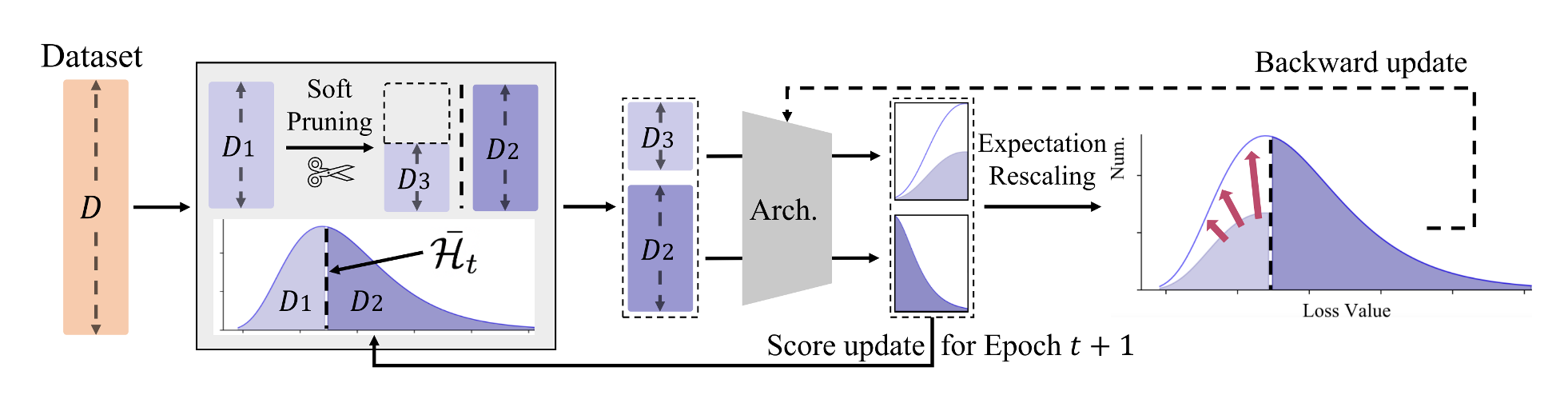
How does Infobatch work?
We provide a plug-and-play pytorch implementation for Infobatch (and still under active development). With the following three lines, you can easily apply Infobatch to your training code.

Here we give a brief explanation of InfoBatch algorithm. First, InfoBatch will randomly drop 1-ratio of the samples with loss smaller than averaged loss over all samples. The paper discusses more complicated strategies, but for now we implement the simplest one, which is already very effective. Second, InfoBatch will rescale the loss of the remaining samples with loss smaller than averaged loss by a factor of 1/(1-ratio). This is to ensure that the lossless performance is maintained. Third, at the end of training, InfoBatch will pass through all the samples to mitigate forgetting. The hyperparameter delta controls the ratio of epochs performing dataset pruning on the fly. ratio=0.5, delta=0.875 are good hyperparameters to start with.
In the code above, the first change wraps the dataset and the order index is organized. We need to pass the InfoBatch sampler to the dataloader constructor in the second change. The last change rescales the loss and update the sampler with the loss between the forward and backward pass. For more mathematric discussion and ablation studies, please refer to the paper. For parallel training, please refer to the code.
A wide range of applications
The idea behind Infobatch is very simple, but it is very effective in a wide range of applications.
- Image classification: While all previous methods fail to maintain the lossless performance, Infobatch can achieve 40% speedup without loss of accuracy.
- MAE pretraining: Infobatch saves 20% of training time for ViT and Swin without loss of downstream accuracy.
- Semantic segmentation: Infobatch saves 40% of training time without degradation of mIoU.
- Diffusion model: Infobatch saves 27% of training time with comparable FID score.
- LLM instruction fine-tuning: Infobatch can save 20% of training time.