Jul. 2023 | CAME Optimizer: Adam Performance with Adafactor Memory Requirements
Zangwei Zheng, zangwei@u.nus.edu
National University of SingaporeACL 2023 Outstanding Paper Award
Other version: [arXiv] [Code] [中文]
Discuss on twitter with the author.
TL;DR
In language model training, optimizing memory usage is crucial, especially with the increasing parameter sizes of large language models (LLMs). The CAME optimizer, introduced in our work, addresses this issue by reducing memory consumption while maintaining performance on par with the Adam optimizer.
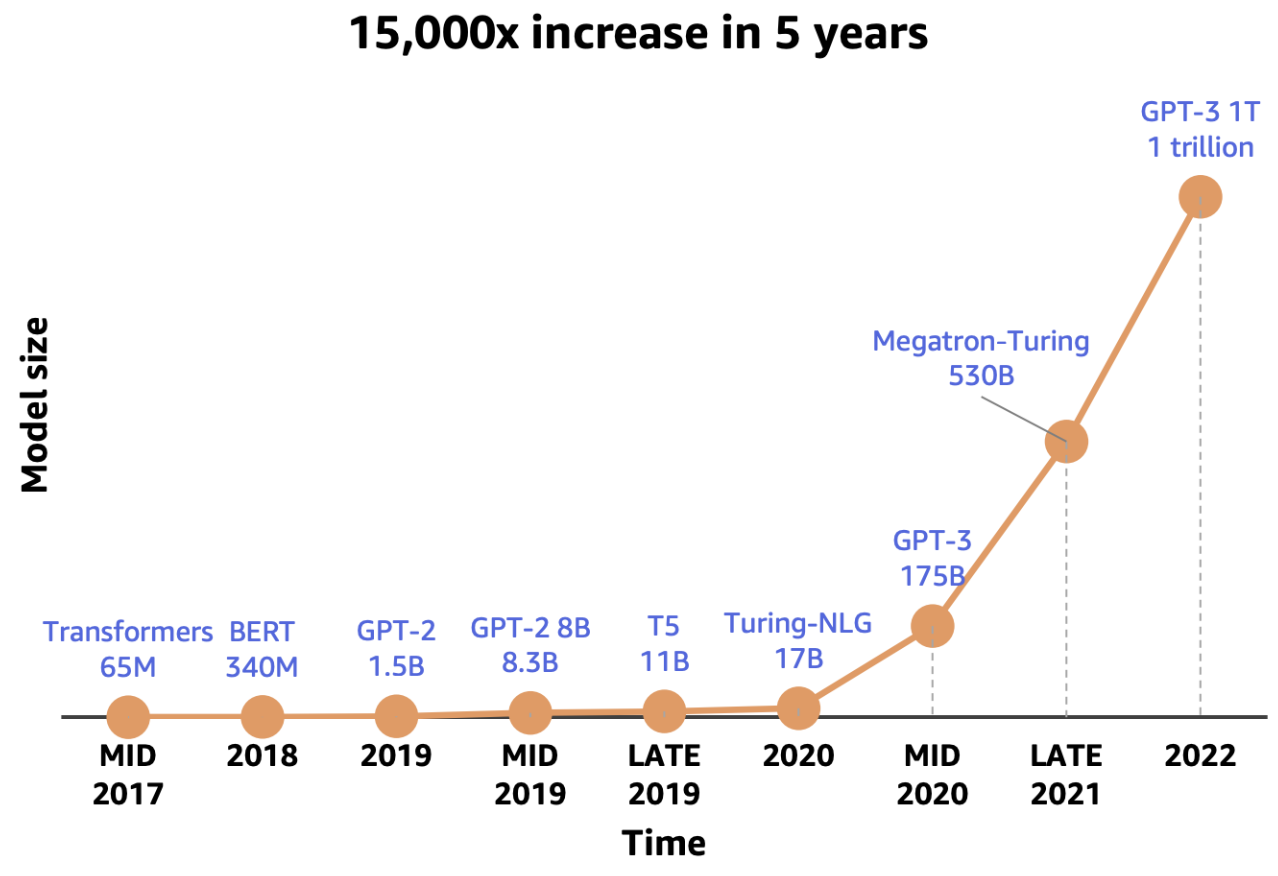
LLM Training Requires Large Memory
The growth in the number of parameters in LLMs has significantly increased the memory requirements for training. Optimizers contribute a substantial portion to the overall memory consumption. For instance, the Adam optimizer requires six times more memory (due to m, v states, and fp32 copies) compared to the memory used by the model itself in mixed precision training.
To mitigate memory usage, an effective approach is to optimize the memory footprint of the optimizer’s state. Adafactor, a widely-used optimizer at Google, achieves this by employing matrix decomposition to save memory for the second-order momentum state (v):
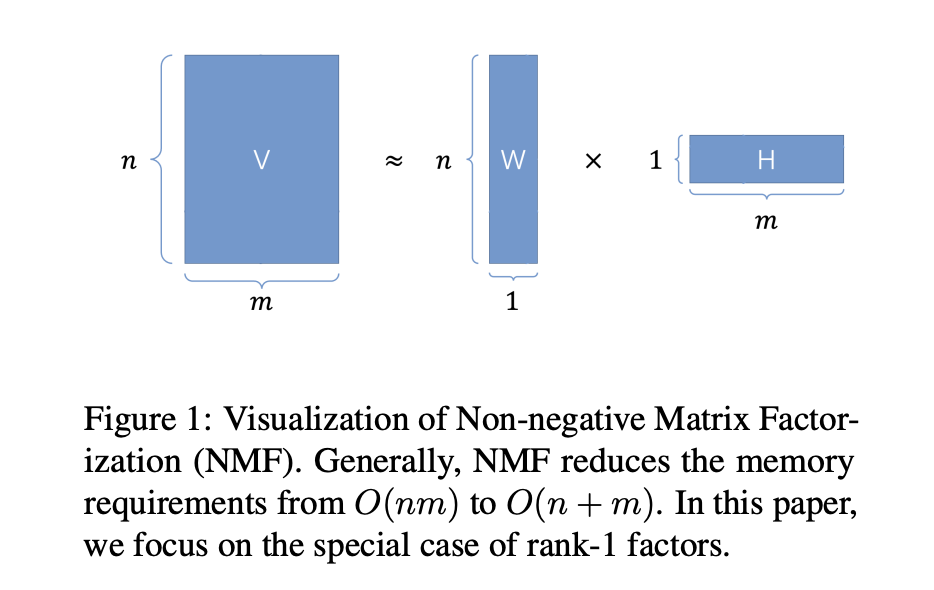
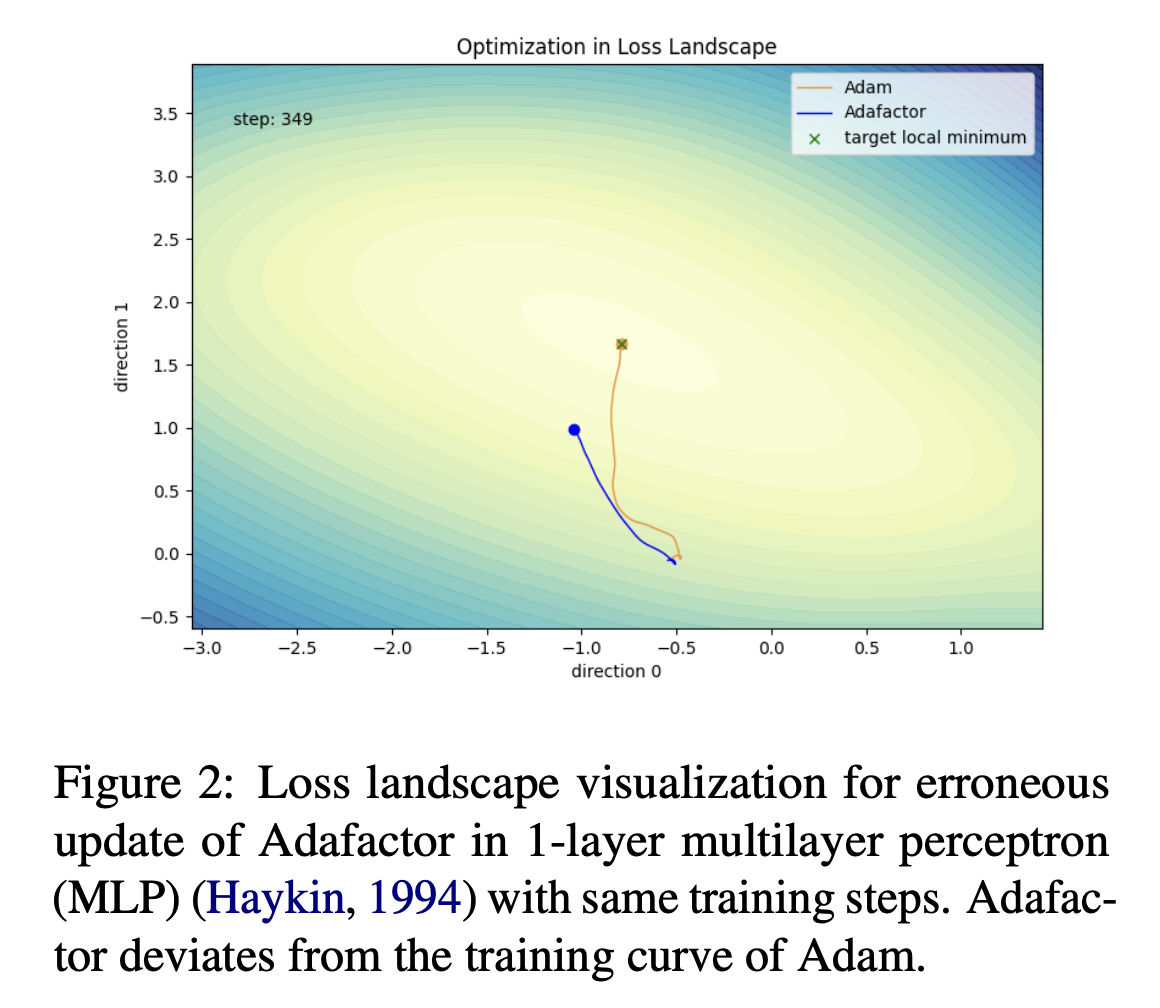
This reduction in memory usage from O(nm) to O(n+m) results in a linear cost. However, the introduced matrix decomposition introduces instability in updates, leading to performance degradation in large-scale language model pretraining tasks. We compare the optimization process of Adam and Adafactor in a 1-layer multilayer perception training task, and it is evident that Adafactor deviates from the training curve of Adam.
Confidence-guided Adaptive Memory Efficient Optimization (CAME)
To address the instability issue of Adafactor, we propose the CAME optimizer, which incorporates confidence-based update magnitude correction and applies non-negative matrix factorization to the introduced confidence matrix. This approach effectively reduces additional memory overhead. The CAME algorithm is outlined below, with the black fonts denoting similarities to Adafactor and the blue fonts representing the modifications.

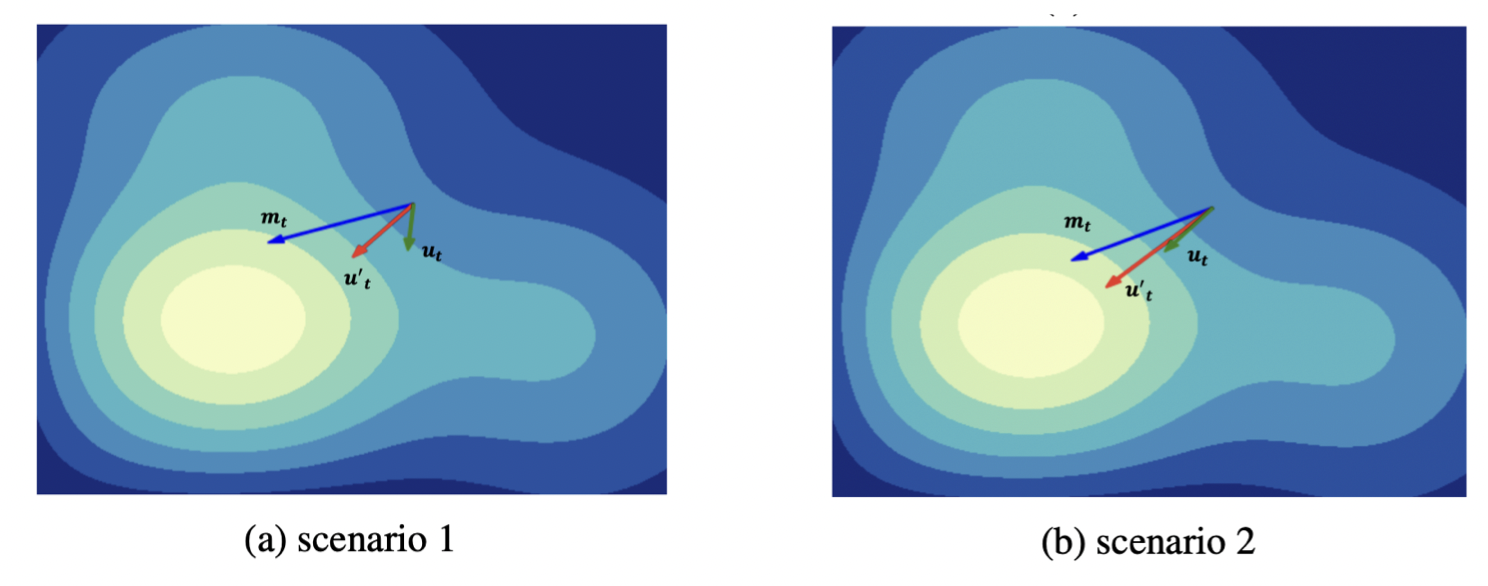
The key distinction between CAME and Adafactor is the introduction of a confidence matrix $U_t$ in CAME, which is utilized to correct the update magnitudes. The underlying rationale is straightforward. Adafactor may exhibit approximation errors that can lead to deviations in the updates. The introduction of update momentum (introduced in Adafactor) smooths the updates. In CAME, we further diminish updates that deviate significantly from the momentum and encourage updates with smaller deviations. The impact of this correction can be observed in the following figure.
Experiments
We evaluate the CAME optimizer on multiple widely-used large-scale language model pretraining tasks, including BERT and T5. The results are summarized below. Our CAME optimizer outperforms Adafactor and achieves comparable or even superior training performance to the Adam optimizer, with memory usage similar to Adafactor and better robustness in large-batch pretraining scenarios.
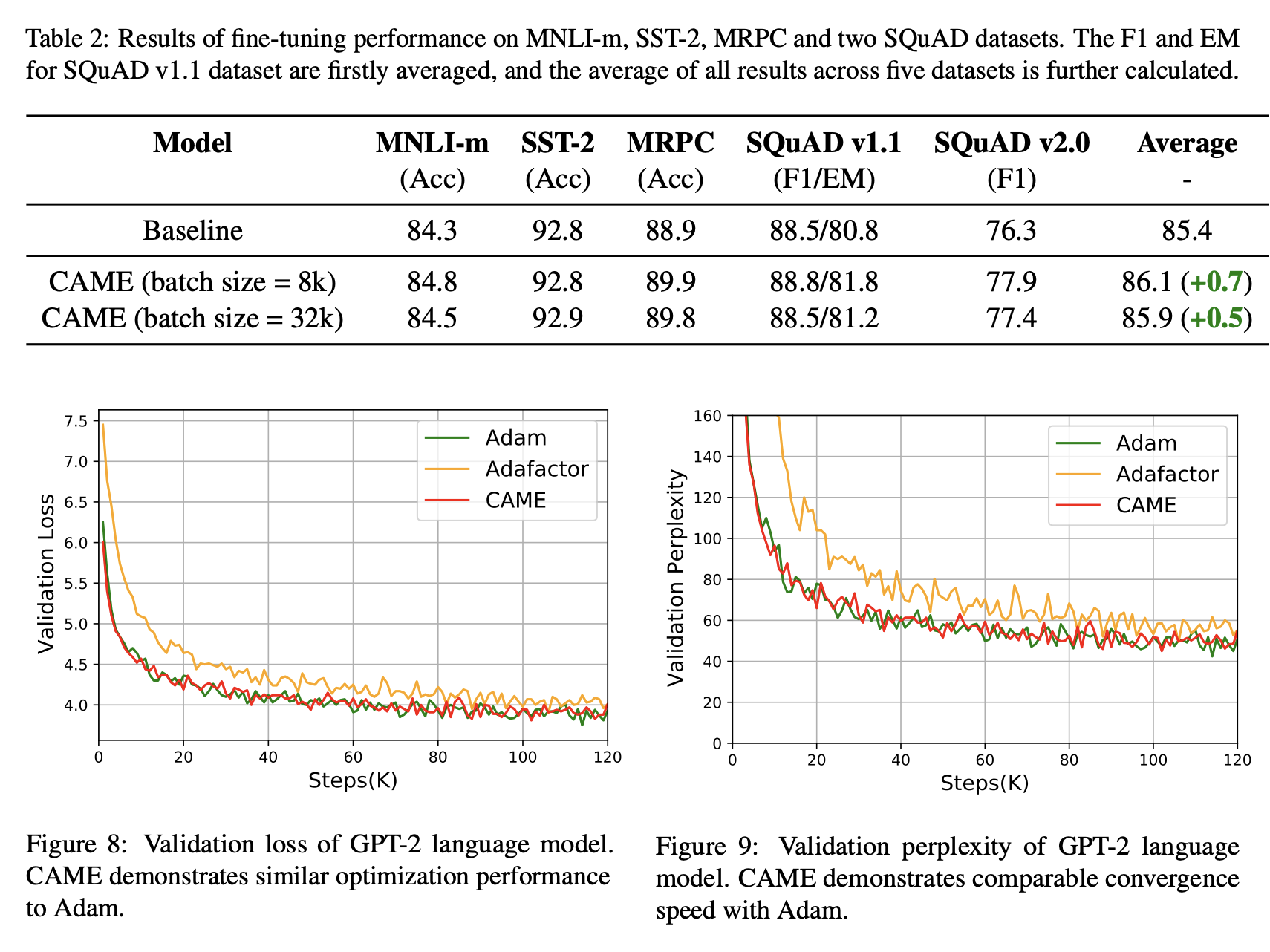
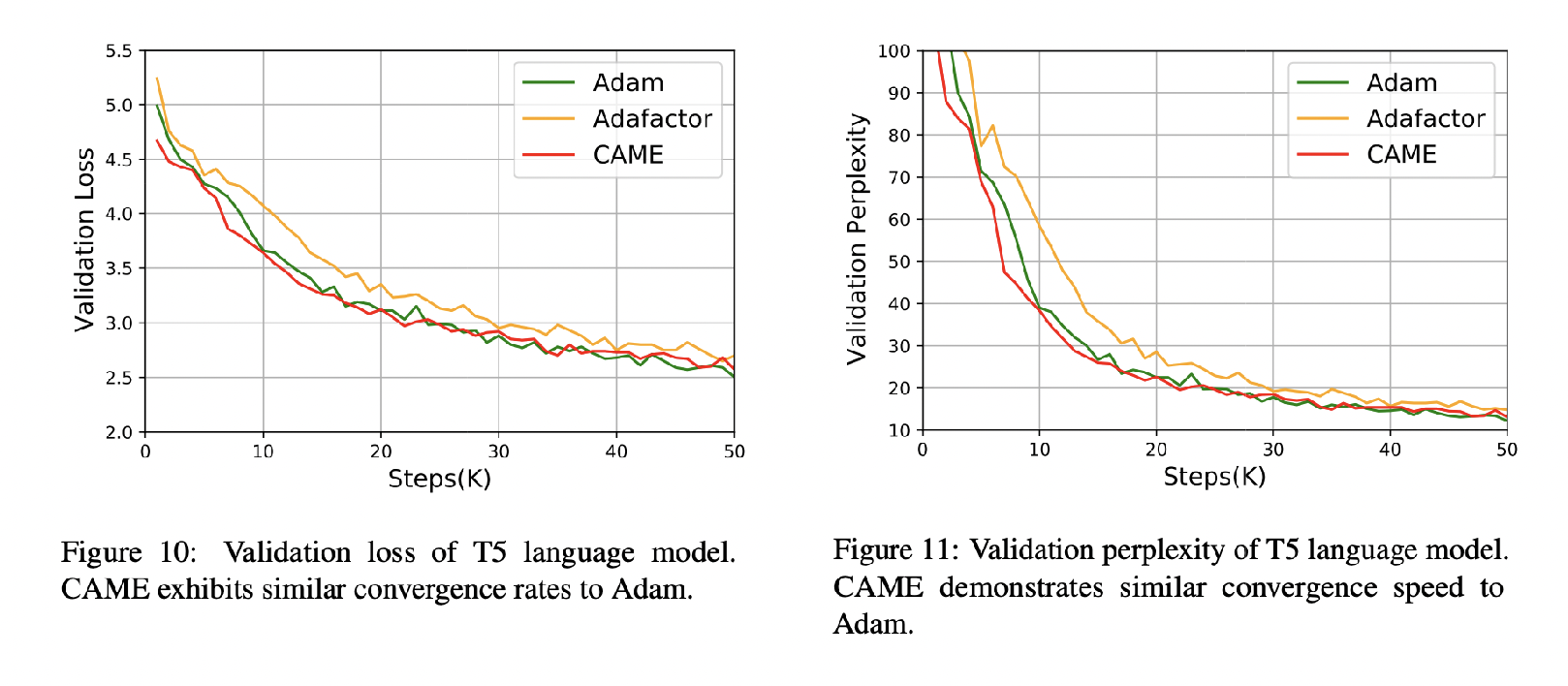
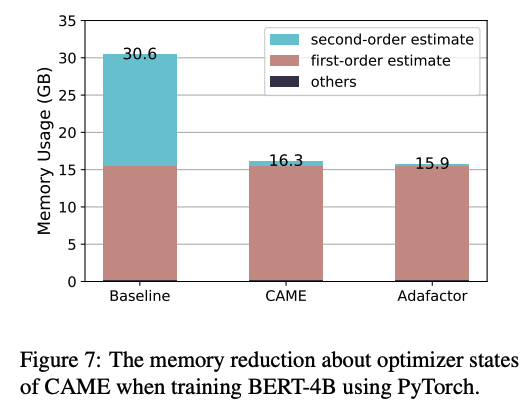
Future Work
We are actively developing a plug-and-play optimizer repository that can seamlessly integrate into existing training pipelines, including popular models like GPT-3 and LLaMA. Additionally, we are working on removing the need for a momentum state in both the Adafactor and CAME optimizers, which will further simplify their implementation and usage.
Furthermore, with the increasing size of GPU clusters, we are exploring the potential of applying the CAME optimizer to even larger batch sizes. This investigation aims to leverage the benefits of CAME in memory optimization and performance enhancement on a larger scale.
Our ongoing research and development efforts in these areas demonstrate our commitment to providing practical solutions for memory-efficient and high-performance optimization in language model training.